Egaroucid 技術解説
ここに書いた内容は初心者向きではありません。オセロAI初心者向け記事はこちらに書きました。
このページは雑多なオセロAI関連の技術文書です。のんびりと気が向いたときに書き足していきます。章立ての順番に意味はありません。読みたいところだけをぜひお読みください!
論文などでこの技術解説を利用することを歓迎します。引用する際は、以下のような形式を参考に、論文の引用フォーマットに合わせていただけると幸いです。
日本語の場合: 山名琢翔: Egaroucid 技術解説, https://www.egaroucid.nyanyan.dev/ja/technology/explanation/
英語の場合: Yamana, Takuto.: Egaroucid Technology Explanation, https://www.egaroucid.nyanyan.dev/ja/technology/explanation/
最終更新: 2025/11/29以降は各節の末尾に掲載
ボードの実装
オセロAIを作るにあたって、どんな方法を使うにせよボードの実装(オセロのルールの実装)は必要です。ここでは、Egaroucidで使用しているビットボードをメインに、様々なTIPSを記述します。
ビットボード
オセロAIにおいて一番おすすめなボードの実装方法がビットボードです。Egaroucidもビットボードを使っています。ビットボードはうまく書けばとんでもなく高速にオセロのルール(合法手生成、返る石の計算)を実行でき、さらにメモリ使用量を抑えられます。
ビットボードでは、オセロの64マス(8x8)の盤面を扱うため、64bit整数2つを使い、自分の石のありなしを表すのに64bit、相手の石のありなしを表すのに64bit使います。これで、オセロの盤面をたった128bit(64bit整数2つ)で表せました。非常にメモリ使用量が少なく済みます。
メモリ使用量が少ないこと自体、キャッシュヒット率が上がって高速化につながる可能性がありますが、ビットボードにはメモリ効率以上に、単純に計算スピードを上げることができるという良さがあります。計算機はそもそも内部的に情報をビット列で持っているため、ビット演算が非常に得意、つまりビット演算を爆速で実行できます。そして、ビットボードを使うとオセロのルールをビット演算で記述できます。さらに、64bit整数で64マスを表せるので、1回の演算を行うことで複数のマスに影響を与えることができます。つまり、少ない命令数でオセロのルールを実装できてしまうのです。そもそも高速なビット演算を、少ない命令数だけ使うため、爆速なのです。
SIMDによる高速化
ビットボードはそれ自体で非常に高速ですが、SIMD (Single Instruction, Multiple Data: 1つの命令を複数のデータについて同時に行う) によってさらなる高速化が可能です。ビットボードはビット演算を多用する関係でSIMDと非常に相性が良いところが魅力です。Egaroucidでは様々な方からの技術提供(GitHubのプルリクエスト)もあり、SIMD化による最大限の高速化を行っています。ただし、SIMD (特にAVX2という命令セット) は一部のCPU (2013年以前のもの) では使えないため、EgaroucidではSIMDを使わないバージョンもGeneric版として公開しています。
SIMDはCPUレベルの命令として128bitや256bit、さらには512bitなどのビット列を一斉に処理します。これをうまく使えば、例えば64bit整数4つに対する各1回の計算(合計4回)を、256bitに対する1回の計算に置き換えることができてしまいます。これによってかなりの高速化が可能です。Egaroucidでは、SIMDを使った場合、SIMDを使わない場合と比べて1.5倍速程度になっています。
SIMDによる高速化は奥原氏によるEdaxのAVXを使ったビットボード高速化の解説が大変参考になります。
いつかこのサイトでもSIMDについて解説したいのですが、私自身の技術力不足、および奥原氏による解説が非常に素晴らしいという理由で後回しになっています。
Perftの活用
ボードはビットボード以外にも様々な方法で実装できますが、どのような方法にしても実装ミスがないかを確かめておく必要があります。また、ボードの処理は高速にできると良いわけですが、変更前後でどれくらい性能向上があったのかをしっかり確かめることが必要です。
こういったデバッグ・検証用途では、Perftという手法が便利です。Perftは決められた深さまでゲーム木を全部展開し、葉ノードの数を数える手法です。葉の数を数えるので、ボードの実装にバグがあったらすぐに気付けます。また、ゲーム木展開で合法手生成と返る石の計算を大量に行うので、これらのボード操作のスピードが顕著に実行時間に反映されます。なお、Perftは"PERformance Test, move path enumeration"の略だそうです(Chess Programming Wikiより)。実装方法はChess Programming Wikiに詳しく記載があります。
なお、オセロでは9手以降で終局が発生します。終局した場合、そのノードはゲーム木の葉なので、指定した深さに達していなくとも1枚の葉としてカウントします。
オセロにおけるPerftの値(深さを指定したときのゲーム木の葉の数)は以下の通りです。2種類の値を記載しましたが、モード1が一般的なPerft、モード2がEgaroucid独自のPerftです。モード1はパスを1手にカウントしていますが、モード2はパスを0手としてカウントしています。オセロにおいては1手で1マス埋まるため、AIの実装においてはパスを0手としてカウントすることが往々にしてあります。そのため、Egaroucidではモード2としてこれを用意しました。以下はEgaroucidで計測したものですが、モード1の値についてはこちらにも記述があります。
| 深さ | 葉の数(モード1: パスは1手) | 葉の数(モード2: パスは0手) |
|---|---|---|
| 1 | 4 | 4 |
| 2 | 12 | 12 |
| 3 | 56 | 56 |
| 4 | 244 | 244 |
| 5 | 1396 | 1396 |
| 6 | 8200 | 8200 |
| 7 | 55092 | 55092 |
| 8 | 390216 | 390216 |
| 9 | 3005288 | 3005320 |
| 10 | 24571284 | 24571420 |
| 11 | 212258800 | 212260880 |
| 12 | 1939886636 | 1939899208 |
| 13 | 18429641748 | 18429791868 |
| 14 | 184042084512 | 184043158384 |
| 15 | 1891832540064 | 1891845643044 |
Egaroucidではコンソール版のバージョン7.4.0からperft機能を搭載しました。これは主に開発者である私がデバッグ・高速化を容易に行うためです。他の開発者も、デバッグ用途やスピード比較用途に利用できると思います。
最終更新: 2025/11/29
探索アルゴリズムの選定(minimaxかMCTSか)
ゲームAIを作る上でのアルゴリズムは古くからminimax法が有名でした。1997年にチェスで人間を打ち負かしたDeep Blueも、同年にオセロで人間を打ち負かしたLogistelloも、このminimax法から派生するアルゴリズムでした。しかし、2000年に入るとMCTS(モンテカルロ木探索)が発展し、さらに2010年代にはMCTSをさらにアップデートしたPV-MCTS (Policy Value MCTS)が発展しました。2016年に囲碁で人間を打ち負かしたAlphaGoはPV-MCTSです。
この2つのアルゴリズムは根本から違うものです。例えば将棋AIではminimax系統とMCTS系統でそれぞれ良さがあるようですが、オセロにおいてはどちらを使うのが良いでしょうか。オセロにおいてminimax系統とMCTS系統のどちらが良いか、結論を簡単に出すことはできないと思います。ただ、Egaroucidではminimax系統のNegascout法を使っています。
ここでは、Egaroucidでminimax系統を採用した経緯を含め、オセロにおけるminimax系統とMCTS系統のどちらを採用するかという議論を書いてみます。
評価関数の精度
minimax系統のアルゴリズムでは、計算量の問題で終局まで読みきれない場合には終局前に評価関数を使って、それをそのまま終局まで読んだ確定値と同じように利用します。つまり、評価関数の精度が悪ければ必然的にAIは弱くなります。
MCTSはもともと囲碁のために発展したアルゴリズムでした。囲碁ではminimax系統のアルゴリズムが使いにくかったのです。その原因が囲碁の評価関数の作りにくさにあったといいます。将棋ではNNUEという評価関数が強いようで、NNUE+minimax系統の組み合わせとPV-MCTSが拮抗しているらしいです。
オセロにおいては、Logistelloに関する論文(Buro 1997), (Buro 1999)でパターンを用いた評価関数が提案されてから、(それなりに)手軽に高精度の評価関数が作れるようになりました。ですので、評価関数の精度は、オセロにおいてはあまり問題になりません。この点で、オセロでminimax系統が向いていると言えます。
参考文献
- (Buro 1997): Michael Buro: Experiments with Multi-ProbCut and a new high-quality eval-uation function for Othello, NECI Tech. Rep. 96 (1997)
- (Buro 1999): Michael Buro: From simple features to sophisticated evaluation functions, in Proc. 1st Int. Comput. Games (Lecture Notes in Computer Science), 1999, pp. 126–145, PDF
最終更新: 2025/11/29
合法手数
MCTSは評価関数を必要としない以外にも利点があります。それは、合法手が多いゲームでもそれなりの性能が出せるところです。MCTSは囲碁のために考案されましたが、実際、囲碁は合法手が非常に多いこともあり、minimax系統のアルゴリズムには向かないそうです。
各局面の合法手数を$b$、探索する深さを$d$とすると、minimax法の計算量は$b^d$、そしてminimax法に効果的な枝刈りを施したαβ法は$\sqrt{b^d}$です。合法手が多いゲームでは指数関数の底が大きくなるため、計算量が爆発しやすくなって困ります。囲碁などのゲームではこの問題が非常に大きく、そのためにminimax系統が向かないのです。しかし、オセロに関して言えば合法手は対局全体を通して10手前後と比較的少なめで、この点でもオセロはminimax系統に向いているでしょう。
スコアを最大化するゲームである点
オセロは囲碁や将棋と違い、勝ち負けを争ううえで、終局時における相手との石の枚数の差(最終石差)を最大化するというタスクのあるゲームです。実際、人間によるオセロの大会では、一般に、勝敗が同じ人が複数人いた場合には石差の合計が大きい人(大勝をいっぱいした人)が上の順位になります。
経験的にMCTS系統ではスコアを最大化するゲームが苦手と言われます。そのため、オセロではこの点でminimax系統が良いと言えると思います。
ただ、2024年にMCTSでスコアを最大化するゲームを扱う手法が提案され(神子島・坂地・野田 2024)、この手法が非常によくできているという印象を受けました。もしかしたら、スコア最大化の問題はMCTS側の工夫で解消できる問題かもしれません。
参考文献
- (神子島・坂地・野田 2024): 神子島一弥, 坂地泰紀, 野田五十樹: Self-Playを用いた深層強化学習におけるスコア分布予測型モデルの提案, 研究報告ゲーム情報学(GI), Vol. 2024-GI-51, No. 29, pp. 1-8
最終更新: 2025/11/29
完全読みの実装
オセロでは、終盤30手(オセロ自体が60手で必ず終局するため、終盤というよりはど真ん中ですが…)程度は終局まで個人向けパソコンでも数秒から10秒程度で完全読みできます。完全読みは名前の通り、終局まで厳密に読み切ってしまうため、ミスをする余地が(バグがなければ)ありません。そういうわけで、特にオセロではこの完全読み(または、明らかな悪手を省く工夫をした読み切り)をいかに早い段階で行うかが強さに直結します。
MCTS系統のアルゴリズムは完全読みのような厳密な探索には向かないため、完全読みはminimax系統で行います。そのため、中盤探索も含めて全てminimax系統でオセロAIを作ってしまえば、実装が簡潔になると思われます。
双方のアルゴリズムで実験してみた結果
CodinGame OthelloというオセロAIのコンテストに参加しているときに、minimaxとMCTSを両方試してみたのですが、どうも私の実装ではMCTSがあまり強くなりませんでした。あくまでも当時の私の実装力の範囲の話なので、本当にオセロにMCTSが向いていないのかを議論することはできませんが、その時にとりあえずminimaxを使おうという結論になりました。
ただ、このコンテストの上位にMCTS系統のような雰囲気の打ち方のAIがおり、本当にMCTSが弱いというよりは、私の実装力の問題である説が濃厚です。
個人的な面白さ
これは単純に私の趣味です。私は個人的に、人間が頑張ってチューニングしたコードが大好きですし、自分でもコードをよく吟味してチューニングしたいと思ってます。minimax系統のアルゴリズムはその点、微々たる高速化が全体のスピードに多大な影響を与えるという点で、個人的に好みでした。
将棋AI開発者とお話しをすると思うのですが、minimax系のオセロAIはMCTS系の将棋AIなどと比べて、些細な高速化が有効に働きやすいようです。些細な高速化が大好きな私としては、minimax系の方が面白そうに感じました。ただ、もちろん将棋AIはスピードがいらないかと言うとそんなわけはないはずで、将棋は将棋で細かな高速化を頑張っているはずです。
評価関数のモデル
既存の強豪オセロAIに広く使われているパターン評価は、Logistelloで提案され(Buro 1997), (Buro 1999)、今日のEdaxまでほとんど形を変えずに受け継がれています。Egaroucidもこのパターン評価をベースにしていますが、少し特徴量を追加しました。
Egaroucidでは石自体をパターンとして評価する既存手法に追加の特徴量を加え、全ての得点の和を評価値としました。評価関数は1手を1つのフェーズとして合計60フェーズ用意し、それぞれ大量の学習データ(全フェーズ合計で18億局面)を用意し、Adamで最適化しました。
参考文献
- (Buro 1997): Michael Buro: Experiments with Multi-ProbCut and a new high-quality eval-uation function for Othello, NECI Tech. Rep. 96 (1997)
- (Buro 1999): Michael Buro: From simple features to sophisticated evaluation functions, in Proc. 1st Int. Comput. Games (Lecture Notes in Computer Science), 1999, pp. 126–145, PDF
最終更新: 2025/11/29
石評価パターン
Egaroucid 7.7.0で盤面のパターンとして使ったのは以下です。
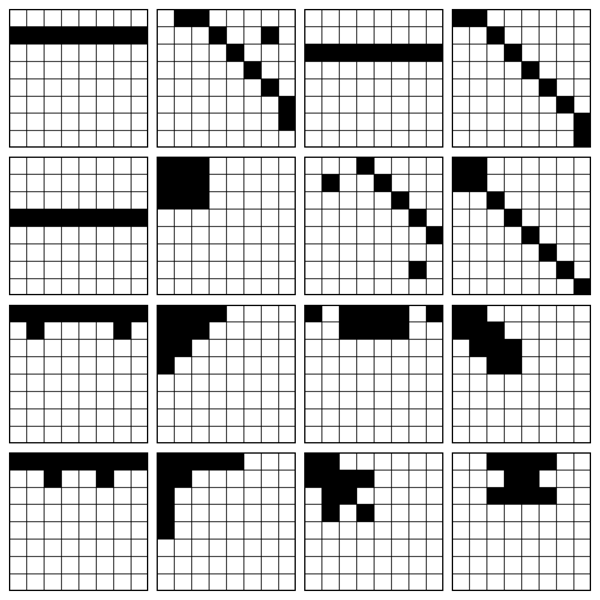
オセロでは着手可能数が形勢の評価に有効に使えるため、石のパターンから着手可能数について潜在的に情報が得られるよう、全ての3マス以上の直線的な連続パターンを網羅していると良いです(Buro 1999)。
これらのパターンを回転や折り返しして、以下に示す64個の特徴量を生成し、これらの特徴量につけられた点数の合計を評価値としています。

それぞれのマスがいくつの特徴量に属しているのかを示したヒートマップは以下の通りです。
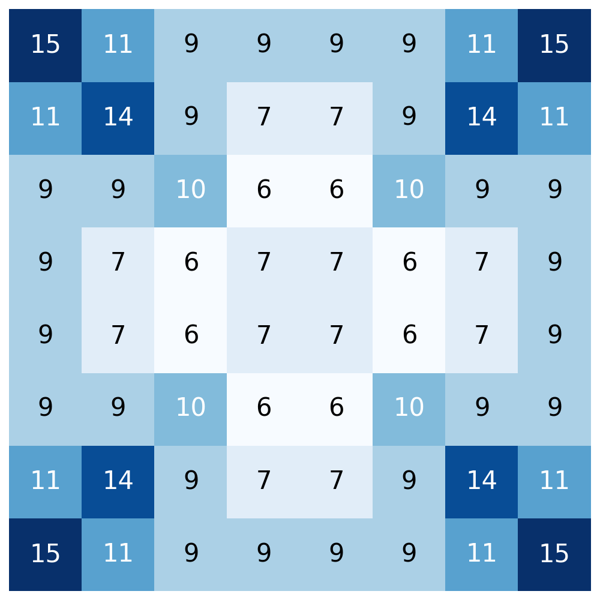
オセロでは一般に隅や辺の形が形勢に強く影響すると言われています。そのため、隅や辺のマスは多くのパターンで含むようにしています。
参考文献
- (Buro 1999): Michael Buro: From simple features to sophisticated evaluation functions, in Proc. 1st Int. Comput. Games (Lecture Notes in Computer Science), 1999, pp. 126–145, PDF
最終更新: 2025/11/29
その他の特徴量
Egaroucidではさらに、追加の特徴量として手番側の石数を使っています。なお、Egaroucidでは盤面上の(双方の合計の)石数によって60フェーズに分けた評価関数を使用しているため、手番側の石数を使うだけで、相手の石数も暗に特徴量に含んでいます。
精度と速さのトレードオフ
評価関数は一般に、複雑なモデルを使えば精度が高まり、強くなります。しかし、複雑なモデルは往々にして計算時間が多くかかります。そうすると時間あたりに先読みできる深さが浅くなり、時間あたりの強さでは逆に弱くなってしまうかもしれません。特にαβ法系統のアルゴリズムは、評価関数を実行する回数がどうしても多くなり、評価関数の速さは探索全体の速さに強く影響を与えます。
しかし、逆に評価関数が正確になると正確なmove orderingができ、αβ法などでは訪問ノード数を減らすことができ、結果的に高速になるという考え方もできます。ゲーム木は深さに対して指数的に大きくなるため、深い探索を行う場合には、評価関数が多少複雑である方が訪問ノード数を減らせて探索全体の高速化ができる可能性もあります。
これらの2つの観点は、結局はバランスの問題だと思います。EgaroucidではEdaxに比べて少し複雑な評価関数を用いており、そのためにEdaxよりも評価関数が遅いです。なお、Egaroucid 6.X.Xでは上記のパターンや特徴量に加えて着手可能位置を使ったパターンも使っていました。Egaroucid 7.X.Xからは着手可能位置のパターンを評価関数から除外しました。これは、正確性を少しだけ犠牲にして速さを得たということになります。ただ、Egaroucid 7.X.Xでは学習データの見直しを行い、Egaroucid 6.X.Xの評価関数と遜色ない強さに仕上げています。
評価関数を複雑にすると遅くなる、ということをより具体的に考えると、結局はメモリへのランダムアクセスがボトルネックになりがちです。これについては、ある程度は仕方のない問題です。使うパターンの数や大きさによってメモリ参照のスピードは変化しますので、限界まで高速化することを考える場合には選ぶパターンについてよく吟味する必要があると思います。とは言いつつ、現時点では色々と試してみた結果あまり効果がなかったのですが…
NNUE評価関数
将棋AIで開発され、後にチェスAIにも輸入された、 NNUEという評価関数があります。NNUEは、簡単に言えばごく小さなニューラルネットワークを評価関数として用いるものです。将棋やチェスでは成功を収めているこの評価関数がオセロにおいて使えないか、少し実験してみました。結論を言うと、「完全にダメだと断定は全くできないが、高性能な評価関数を作るのは結構大変そう」というのが今のところの見解です。
ニューラルネットワークと聞くと遅そうなイメージがあり、遅いとαβ法のようなアルゴリズムには適さないような気がします。しかし、NNUEはニューラルネットワークの規模を非常に小さくし、入力層を着手ごとに差分計算したり、中間層をSIMDで高速化したりすることでCPU上で十分実用的なスピードにしています。実際、将棋では既存の3駒関係を使った評価関数に遜色ないスピードだそうです。
NNUEの良さは、非線形な評価関数であるところです。パターン評価や将棋の3駒関係は、どちらも線形な評価関数であるため、その表現力には仕組み上の限界があります。しかし、ニューラルネットワークであればこの限界がないというわけです。
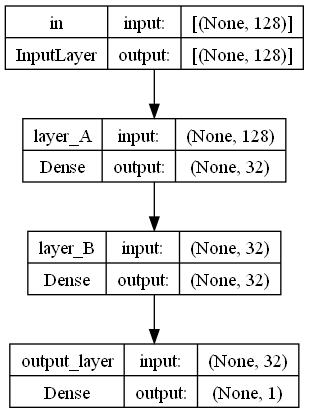
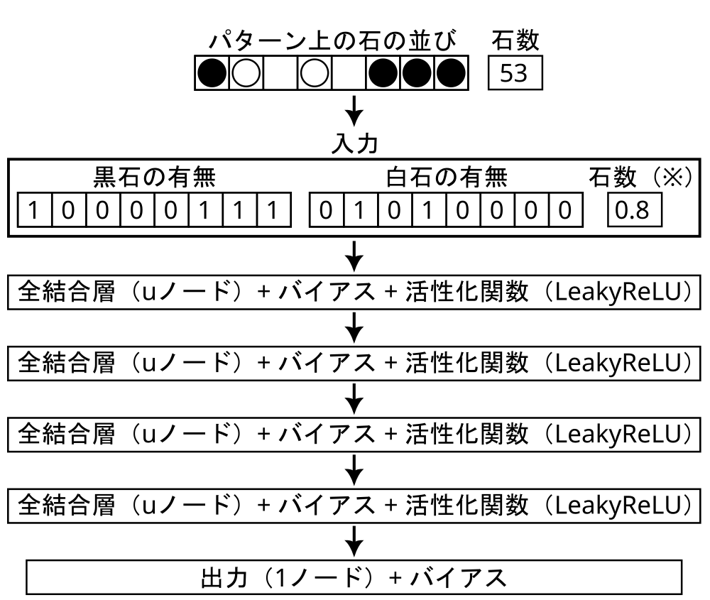
この規模でオセロに対して十分に学習できるかを試してみました。実験として黒石の有無64マス、白石の有無64マスの合計128個の入力(つまり、ビットボードそのまま)に対して中間層として32ノードの全結合層を2つ、活性化関数をReLUとしたモデル(下図参照)を仮で作り、十分な学習データで学習してみました。
その結果、既存のパターン評価には評価性能が届きませんでした。具体的には、評価関数の学習データに対する平均絶対誤差(MAE)について、パターン評価は3.5石程度なのに対し、このテストモデルは5.4石程度でした。NNUEの良さは非線形性による評価性能の向上だったので、オセロにおいて、この実験ではNNUEの優位性を感じることはできませんでした。もしNNUEをオセロに使うのであれば、NNUEをオセロにおいて実用するには入力層の工夫か中間層のボリュームを増やすことが大切だと感じています。ただ、これらの解決法は推論スピードを損ねる可能性があるため、スピードとの兼ね合いを見ながら検討する必要があります。
ちなみに、上図くらいの大きさのモデルであれば、確かにかなり高速にCPUで推論できそうでした。ですので、NNUEはもう少し頑張ってみる価値があるような気がします。
評価関数の学習データ
評価関数のモデルを決めたら、そのモデルに含まれるパラメータを最適化(学習)するために、大量のデータを用意します。ここでは、局面に対して最終石差を予測する評価関数を念頭に記述します。
中盤以降の学習データの作り方
学習データはオセロAI同士の自己対戦によって生成するのが良いでしょう。Egaroucidでは、Egaroucid(の過去バージョン)同士の自己対戦を使いました。AIの強さは、計算スピードと正確さの塩梅を考えてレベル11(中盤11手読み、終盤25手読み切り)としました。
正解ラベルの作り方は色々考えられますが、Egaroucidでは単純に対局の最終石差をそのまま全ての局面で使用しました。データの精度を高めるのであれば学習データに含まれる全ての局面でオセロAIによる先読みを行い、その結果を使うという手法も考えられますが、この方法は非常に時間がかかるため、Egaroucidのレベル11くらいであれば十分強く、自己対戦中の石損は許容できる程度に少ないと考えました。
自己対戦では初手からのみ対戦を行うとデータの多様性を確保できないため、序盤の決まった手数をランダム打ちし、そこから自己対戦を行うようにしました。学習データの質を担保するため、ランダム打ちした部分の局面は学習データから省きます。このとき、ランダム打ちする手数は1つだけではなくたくさん用意すると学習データの質が偏りにくくて良いと思います。Egaroucidでは12手、18手、21手、24手、30手、31手、32手、35手、39手、40手、…、58手など、色々な手数でランダム打ちを行いました。
序盤の学習データの作り方
ランダム打ち+自己対戦による学習データは、数と多様性と精度を全部かなえられる方法ですが、序盤はランダム打ちしているために序盤の学習データが作れないという弱点があります。そのため、序盤の学習データは別の方法で作ります。
序盤はゲームに現れる局面数が非常に少なくなるため、あらかじめ現れる局面を全て列挙し、列挙した局面全てについて既存のオセロAIで決まった手数先読みし、評価値を計算してそれを正解ラベルとしてしまえば良いです。オセロでは11手目までは2000万($2\times 10^7$)程度の局面しか現れないので、Egaroucidでは序盤11手はこの方法を採用しました。このときに調べた結果をオセロの序盤の展開数に書きました。こちらもぜひご覧ください。
実際にデータを作る際には、序盤11手の(ユニークな)展開をすべて列挙して、それらをすべてEgaroucid 7.4.0のレベル17で先読みし、評価値をつけるという作業をしました。
公開されている棋譜データ
Egaroucidは「前回のバージョンを使って自己対戦させ、データを増やす」という手法が取れるため学習データには困らないのですが、最初にオセロAIを作る際には学習データを用意するのが大変だと思います。そこで、インターネット上で公開されている、学習に使える棋譜データおよびデータの変換方法を紹介します。これらがあれば、自前でデータを作らなくてもすぐに学習ができると思います。
評価関数の最適化
評価関数の学習は手動で行うのではなく、計算機によって自動で行います。パラメータ数が十分に少なければ手動でやっても良いかもしれませんが、10個程度であっても手動で調整するのは困難だと思います。
最急降下法
評価関数、特にパターン評価の最適化には、古くから最急降下法が使われてきました。これはLogistelloで考案されたものです(Buro 1997), (Buro 1999)。最急降下法による最適化については、オセロAI Thellの作者による文書(Seal Software 2005)が詳しいです。
Egaroucidでは、ただの最急降下法では収束が遅いので、最急降下法の改良アルゴリズムであるAdamをCUDAで自前実装したものを使っています。なお、GPUメモリ(私の環境は24GB)に全ての学習データを載せることができるため、バッチ化は行っていません。
参考文献
- (Buro 1997): Michael Buro: Experiments with Multi-ProbCut and a new high-quality eval-uation function for Othello, NECI Tech. Rep. 96 (1997)
- (Buro 1999): Michael Buro: From simple features to sophisticated evaluation functions, in Proc. 1st Int. Comput. Games (Lecture Notes in Computer Science), 1999, pp. 126–145, PDF
- (Seal Software 2005): Seal Software: リバーシの評価関数の最適化 (2005)
最終更新: 2025/11/29
学習データと検証データ
学習データと検証データは学習前にランダムに分離されたもので、データの質は同一です。基本的にはEgaroucidのレベル11で対戦した対局データです。その際、序盤何手かをランダム打ちさせ、その後はAIに打たせることでデータのばらつきを発生させました。ランダム打ち部分は学習・検証データに含みません。
フェーズ11(序盤11手まで)までは全ての局面を列挙してそれぞれに正解ラベルをつけることが現実的なので、序盤の展開をすべて列挙してEgaroucidに評価値を計算してもらうことで、学習データを作りました。これらはオセロというゲームにおいて存在しうる全ての局面を網羅したデータのため、学習データと検証データで分離せず、同一のデータを使いました。
テストデータ
テストデータは序盤$N (0 \leq N \leq 12)$手ランダム打ちし、その後はEgaroucidのレベル30で打ち進めたものです。つまり、序盤以降で悪手の応酬になるような局面は含まれていません。ここが学習・検証データとは違うところです。フェーズ11以前のデータは学習・検証データと同様です。
Egaroucid 7.5.0の学習結果
実際に学習データおよびテストデータに対する評価関数の損失をプロットしたものが以下の図です。横軸がフェーズ(何手目かと同義)、縦軸が損失(MSEは2乗誤差の平均、MAEは絶対誤差の平均)です。教師データは最終石差なので、単位はそれぞれ石差の2乗、石差です。
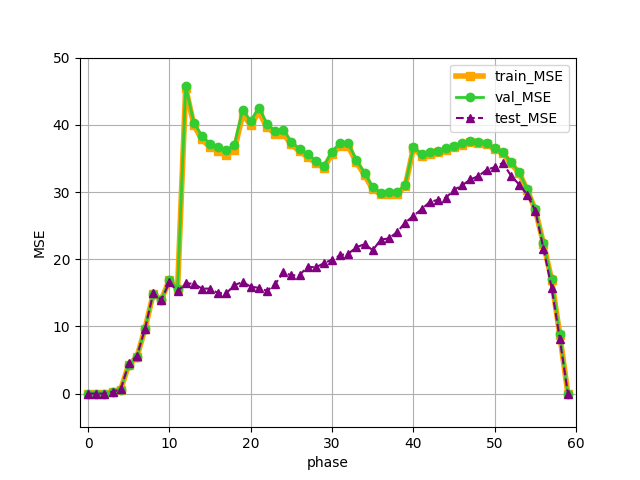
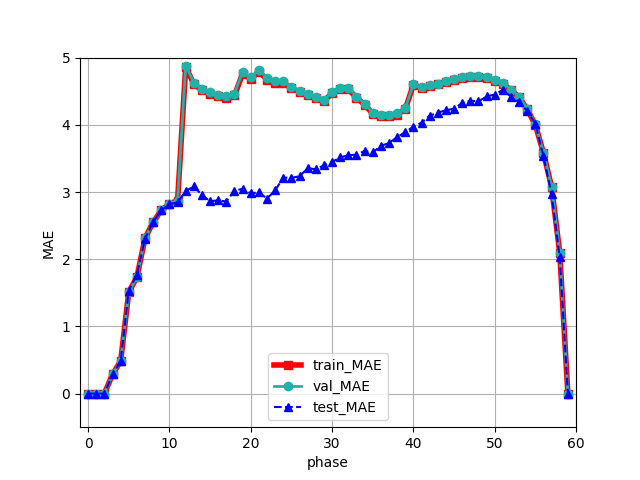
学習・検証データはランダム打ちのタイミングによってフェーズごとにデータの質が異なるため、グラフがいびつな形になっているところがあります。
全体を通して、過学習を起こさずに十分学習できたことが読み取れます。ただ、フェーズ20を過ぎてからtest_mseが上昇しているところを見ると、フェーズ20以降ではオセロというゲームの複雑さに対して評価関数モデルが小さすぎる可能性があることが読み取れます。
深層学習
評価関数の最適化を深層学習によって行うこともできます。これは探索中に推論を回すということではなく、オセロAI起動時にあり得るすべての状態について推論を行い、評価関数のテーブルを復元するという方法です。深層学習によって生まれたパラメータは、往々にして元の評価関数モデルよりもデータ量を小さくできるため、圧縮として活用することができます。また、経験上、深層学習は最急降下法ベースの手法よりも少ないデータで強い評価関数を作りやすいです。
元々EgaroucidはCodinGame Othelloというプログラミングコンテストに参加する目的で制作していました。そのため、このコンテスト特有の「10万文字以内でコードを記述しなければいけない」という制限を守りつつ強い評価関数を作るため、評価関数の圧縮として考案しました(Yamana, Hoshino 2026), (山名・星野 2024), (山名 2022)。
評価関数に登場する各パターンについて、以下のようなニューラルネットワークモデルを構築します。パターンごとに別のモデルを用意して、最終的に全てのパターンの出力結果を足したものを評価値として、正解ラベルと比較します。このとき、1つのパターンには対称な複数のfeatureが存在しますが、これらのfeatureは同一のニューラルネットワークモデルを共有するようにします。
現在のEgaroucidでは、非常に大量の学習データ(32億局面以上!)を作ることに成功したため、深層学習ではなくAdamを使っています。
私の深層学習による学習は、以下の資料にもまとめてあります。
参考文献
- (Yamana, Hoshino 2026): T. Yamana and J. Hoshino, "Compressing the Evaluation Function With Small-Scale Deep Learning on Othello," in IEEE Transactions on Games, vol. 18, no. 1, pp. 128-138, March 2026, doi: 10.1109/TG.2025.3624825.
- (山名・星野 2024): 山名琢翔, 星野准一: 小規模な深層学習による圧縮を利用した強力なオセロAIの開発と評価, 情報処理学会論文誌, Vol.65, No.10, pp.1545-1553 (2024)
- (山名 2022): 山名琢翔: 深層学習による圧縮を利用した強力なオセロAIの制作, 研究報告ゲーム情報学(GI), Vol. 2022-GI-48, No. 5, pp. 1-5 (2022)
- 山名琢翔: オセロAIの教科書 7 【評価】 パターン評価など
最終更新: 2025/11/29
評価関数の高速な実行
評価関数を学習し終えたら、次は探索中に評価関数を実行する部分を作る必要があります。探索中には、評価関数を何回も実行するため、評価関数の実行を高速にしておくことが探索全体の高速化に繋がります。そもそも評価関数のモデルを考える時点で高速な評価関数については考えたわけですが、実装のちょっとした工夫で高速化ができるため、ここにTIPSを記しておきます。なお、ここに書くのは主にパターン評価に関するTIPSです。
差分計算を使う
パターン評価では、全てのパターンについて(対称形も考えつつ)、全ての特徴量のインデックスを計算し、そのインデックスを使って最適化した評価パラメータを表引きします。このとき、特に計算が重い処理は特徴量のインデックス計算です。そのため、ここを差分化してしまうと良いです。
探索開始時に全てのインデックスを計算してしまって、着手のたびに、変わる部分だけ更新すると、特徴量計算が高速になります。着手したときに石を置くマス、およびひっくり返る石のそれぞれについて、そのマスが所属しているパターンに対して$3^x$を足したり引いたりすると差分計算が実装できます。このとき、マスに所属するパターンや$x$は、マスやパターンによって決まる定数なので、あらかじめ計算しておきます。
ここで、計算コスト(計算量+計算回数見積もり)を考えてみましょう。対称形を同一視したパターン(これをEgaroucidではコード内でfeatureと書いています)を$F$個、1マスが所属するfeature数の平均を$G$個、1つのパターンに含まれるマス数の平均を$S$個、着手1回につき返る石の数を$D$個とします。すると、特徴量を全部計算するコストは$O(FS)$、着手にあたって差分計算するコストは$O(GS(D+1))$となります。Egaroucidでは$F=64$、$G=8.8125$、$S=8.8125$です。また、オセロでは平均的に$D=2.24$(詳しくは返る石数の平均値を参照)なので、特徴量を全部計算するときの計算回数は564回、差分計算の計算回数は252回程度で済みます。
オセロAIでは着手のほかに、着手した手を戻す作業も頻繁に使用します。着手を戻す作業も差分計算で実装可能ですが、オセロでは高々60手の着手で終局するため、わざわざ差分計算する必要もありません。あらかじめパターン評価の特徴量を60手分用意して、着手のたびに差分計算しながらコピーを行えば、着手を戻す場合は以前の計算結果を参照するだけで済みます。
SIMDによる差分計算の高速化
パターン評価もSIMDで高速化できます。これはEdax-AVXを書いた奥原氏によるアイデアをEgaroucid向けにアレンジして使ったものです。
差分計算は愚直にやると状態が変化するマスごとに、そのマスが属するfeatureを1つずつループで見ていくようですが、異なるfeatureはそれぞれ互いに独立して計算できるため、ここをSIMDで並列化(っぽく)することができます。
パターン評価に使うインデックスは、パターンに含まれるマス数を10マスまでに制限すれば$3^{10}(<2^{16})$種類で済みます。そのため、16bitあれば全てのインデックスを表現可能なのです。64個のfeatureがある場合、SIMDで256bitのベクターが4($=F(=64)\times16/256$)本あれば良いことになります。4本の256bitベクターに対して、それぞれ「このマスがひっくり返ったらどう操作するか」という情報を前計算しておいて、返る石のマスごとに4回(ベクターの本数)ずつ差分計算すれば良いことになります。
この場合、差分計算の計算量(定数倍が大事なのであえて書くと)は$O(F\times16/256\times (D+1))$となり、計算回数を具体的に計算すると13回程度となります。劇的な高速化です。もちろん、命令ごとにスピードは異なるので、計算回数で安直にスピードを語ることはできないわけですが、とにかく差分計算のSIMD化は恩恵が大きいです。
SIMDによる表引きの高速化
さて、差分計算がSIMD化できたわけですが、実は表引きもSIMD化できます。こちらも奥原氏によるアイデアが原型です。
ここでは、gather命令を使います。gather命令は、SIMDのベクターを32bitずつ区切って読み、それをインデックスとして解釈してメモリ参照を行う命令です。1つの配列を複数回参照するとき、配列の先頭アドレスと、参照したいインデックスをまとめたベクターを入れれば一気に参照できてしまうので便利です。まあ、メモリ参照を行う時点で他の命令と比べると非常に遅いらしいですが、今回はメモリ参照を必ず行わなければいけないので、ここが少しでも高速化できると嬉しいです。
差分計算のためにインデックスを256bitベクター4本として実装していたので、ちょうどそれをそのままgather命令に渡せば良いという点でも、非常に実装しやすいです。ただし、gather命令にはインデックスとして32bitずつ読むもの(_mm256_i32gather_epi32)しかありません。差分計算では16bitのインデックスを使ったので、16bit×16個の256bitを、一時的に32bit×8個の256bitベクター2本に変換して、それをgather命令に渡さないといけません。さらに、gather命令にはメモリ参照を32bit分行うか64bit分行うかの2種類しか存在しません。Egaroucidでは参照すべき配列を16bit整数で表現しているので、無駄に32bit分参照して、上位16bitを捨てる(つまり、0x0000ffffでマスクする)という処理をしています。なんだか無駄ですが、どうしようもありません。
16bit×16個×1本のベクターを32bit×8個×2本に変換するときには、256bitベクターと128bitベクターをunionとしておき、128bit分を読んで、128bitを16bitずつ8個の数値として解釈して、それぞれの数値を32bitに変換する命令(_mm256_cvtepu16_epi32)にかけて256bitベクターを作ると良いです。
gather命令で32bit分メモリ参照を行って、その後上位16bitを捨てる処理についてですが、gatherを使うたびに上位16bitを捨てていては命令が増えてしまいます。Egaroucidでは、そもそも評価関数のパラメータの上限値(=4092)を設定しておき、(上限値)×(gather命令を使う回数(Egaroucidでは8回))=32736が16bitに収まるようにしています。こうすれば、上位16bitを捨てる処理は最後に1回行うだけで済みます。
手の並び替え(Move Ordering)
αβ法の流れを汲むゲーム木探索アルゴリズムでは、各ノードにおいて子ノードを有望な順(良さそうな手の順)に並べて、その順番に探索すると枝刈りが発生しやすくなります。この手の並べ替えをMove Orderingと言います。
ここでは、Egaroucidで使用しているMove Orderingを解説します。色々な特徴を使っていますが、Egaroucidでは常にすべての要素を使うのではなく、状況に応じて使用する特徴、および特徴ごとの重要度を変えています。
浅い探索(以前の探索)の結果
浅い探索の結果で良いと判断された手は、深い探索でも良い手だろう、という考えに基づき、浅い探索の結果をMove Orderingに取り入れています。また、以前の探索で得られた結果が置換表に入っていれば、それを参照するだけとする場合もあります。
ちなみに、αβ法では反復深化を行う場合がありますが、なんでそんな実装をするのかといえば、浅い探索結果を置換表に保持しておいて、Move Ordering時に前回の探索結果を適宜参照し、効率的に探索を行いたいという考え方もできます。もちろん、制限時間内いっぱいに探索したいという需要もありますが。
専用評価関数の値
Egaroucid 7.0.0以降では終盤の探索において、move ordering専用の軽量な評価関数を使っています。通常使う評価関数は終盤のmove orderingに使うには遅すぎるのですが、とは言え終盤のmove orderingも評価関数を使いたいと考え、一部のパターンのみを使った小さな評価関数を作りました。パターンを減らしたことでメモリ参照の回数が減り、非常に高速になっています。また、精度も学習データに対して絶対誤差が4.2石程度と、move orderingに使うには申し分ないと考えています。
Egaroucid 7.4.0の終盤move ordering専用の評価関数では、以下の4パターンを使用しています。これらのパターンは通常の評価関数で使っているパターンの一部ですので、最小限の計算コストしか必要ありません。終盤探索に入ったら、これらのパターンのみ評価値の差分計算を行うようにしています。こうすることで、通常の評価関数の1/4程度のコストで終盤move ordering専用評価値を計算しています。
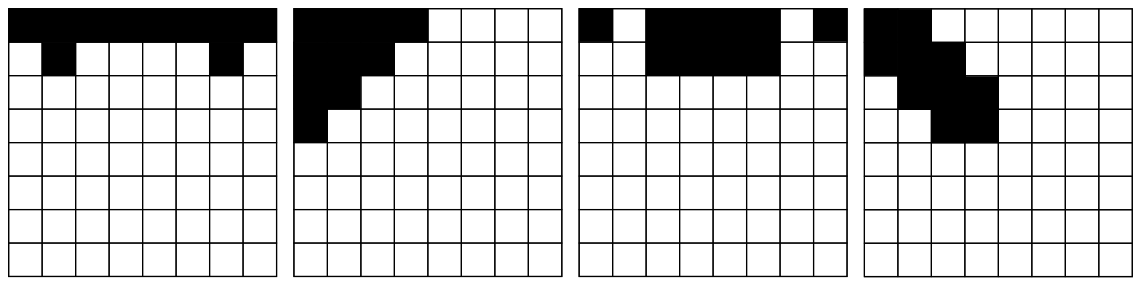
着手後の相手の合法手数
自分の着手後、相手が打てる手が少ない手を優先します。これには2つの意味を考えられます。
まず、オセロというゲームが、相手の打てる場所(より正確には、人力オセロにおける手数(てかず)ですが、単に打てる場所と近似します)を減らしていくゲームであるということです。つまり、相手が打てるところを少なくするような手が、オセロというゲームにおいてそもそも強い手なことが多いのです。
また、合法手が少なければ、単純に展開すべき子ノードの数が少なく済むため、そういった貪欲法を続ければ探索に必要な訪問ノード数を減らせると期待できる面もあります。特にNull Window Search (NWS)においてfail highを狙う場合、fail highさえしてしまえば必ずしも最善手を探索する必要がないため、このMove Orderingが効果を発揮しやすいです。
余談ですが、この「相手の合法手数」という単純な指標が、オセロというゲームの本質としても、さらにゲーム木探索の都合としても、双方から見て非常に合理的なのは、非常に美しい話だと思います。
なお、この合法手数が少ない順に探索する手法を「速さ優先探索」という場合もあるようです。
着手後に自分の石に接している空きマスの数(潜在的着手可能数)
ある手を着手後、空きマスのうち、8近傍のいずれかで自分の石と接している空きマスが少ない手を優先します。これも相手の打てるところを減らしていくという話と大体同じ意味を持ちます。
オセロでは合法手は必ず空きマスに打つ手のみで、かつ、相手の石を挟んでひっくり返すというルールです。ですから、相手が着手する場所は、必ず空きマスであり、かつその空きマスに自分の石が1つ以上接しています。
自分の石に接している空きマスは、今すぐに相手の合法手になることはなくとも、将来的に相手の合法手になる可能性があります。そのため、こういった空きマスの数は少ない方が良いと判断します。この考え方を「潜在的着手可能数」と言ったりもします。
なお、人力オセロでは開放度という考え方がこの潜在的着手可能数と(本質的には)似ていると思います。
局面を4分割したときの空きマスの偶奇(準偶数理論)
オセロでは、相手の石を挟んで返すというルールのため、対局の最後の着手によって置いた石、および返した石はひっくり返されることがありません。さらに、「局所的に」最後の1マスに着手した場合も似た話で、その着手によって置いた石は返した石は、再びひっくり返される危険性が少ないです。そのため、局所的な奇数マス空きには先着し、3マス空きなら自分→相手→自分のように、自分の着手でその局所を終わることが望ましいとされます。人力オセロではこの考え方を偶数理論と言います。偶数理論はその特徴上、オセロの終盤で非常に役立つ戦術です。
オセロにおいて偶数理論を近似的に実装したのが準偶数理論です(私が勝手に名付けました)。偶数理論の実装にあたって難しいのは「局所」の考え方です。そこで強い人同士のオセロの棋譜を眺めると、大抵終盤に空いたまま残るのは隅近くのマスだとわかります。この事実を踏まえて、準偶数理論ではこの「局所」を盤面を4×4の小盤面を4つに分割したものと固定してしまいます。それぞれの小盤面に属する空きマスの数を数えて、奇数空きの小盤面に属する合法手を優先して探索します。
なお、この解説は元々Edaxで使われていた"Parity Ordering"を私が解釈したものです。
着手するマスの位置
人力オセロでも隅が強いと言われるように、オセロというゲームではマスに応じて重要度が変わります。この性質を用いて、例えば隅に着手できるのであれば少し優先するなどの工夫をしています。ただ、この指標は静的なものですし、精度も高くないので、個人的には「他の指標で同点だったら、ランダムに選ぶよりはマシかなぁ」くらいの気持ちで使っています。
置換表(Transposition Table)
ゲーム木は「木」という名前ではありますが、往々にして合流が存在します。つまり、手順違いで同じ局面に到達することが、しばしば発生します。例えばオセロだと虎定石f5d6c3d3c4は、猫系からもこのように到達できますf5d6c4d3c3。このとき、どちらの手筋でも到達する局面は一緒なので、一方を探索した結果をそのままもう一方の探索結果として流用できます。こういった処理を行うために、置換表というテーブルに過去の探索結果をメモしておきます。なお、置換表は合流発生時以外にも、反復深化探索を行ったときに手の並び替え(move ordering)にも役立ちます(むしろ、オセロに限って言えばこの効果の方が大きい気がします)。
置換表はハッシュテーブルとして実装します。しかしゲーム木探索において特殊なのが、必ずしも過去のデータを保持しなければいけないわけではないという点です。置換表にデータがなければまた探索すれば良いだけなので、置換表へのアクセスを高速化することに重点を置き、ハッシュが衝突した場合には過去のデータを書き換えてしまうなどの実装が適しています。
実際には、深い探索は再探索するのが大変なので優先的に残すなどの工夫をしています。また、ハッシュが衝突した場合にはメモリ上で隣の領域(別のハッシュ値が対応しています)が空いていればそこにデータを入れるなどの、軽いハッシュ衝突対策も行います。
ハッシュが衝突した場合に既存データと新データのどちらを残すかという問題ですが、Egaroucidは以下の指標を見て判断しています。上位のものほど優先されます。
- そこに登録してある局面から先に読んだ手数(読みが深いほど探索が大変なので残す価値がある)
- その局面を探索するときのMulti ProbCutの確率(MPCの確率が高いほど探索が大変で値が正確なので残す価値がある)
- 探索の新しさ(新しい探索の結果は優先的に残す)
これらの観点から重要度を計算し、ハッシュ衝突時には重要度の高いものを残すようにしています。さらに、置換表は基本的にリセットしないですべての探索で使い回すことにしています。これによって巨大な置換表をリセットする処理が省けます。ただ、ある程度ずっと置換表を使いまわしていると、古くてコストの高い探索のデータで置換表が埋まっていきます。Egaroucidではこういった状態になったときに全てのデータの重要度を最低値にする処理を入れています。
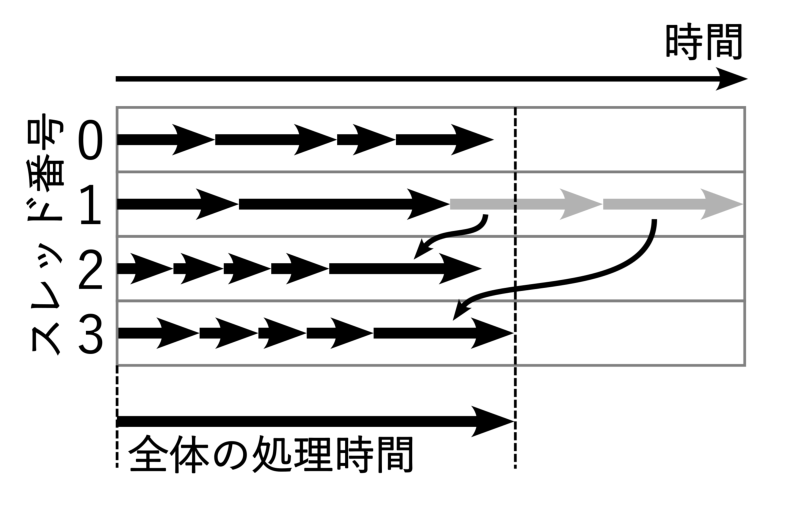
置換表のマルチスレッド化
オセロAIは高速化のため、探索を並列化することが多いです。その際、置換表の扱いはシングルスレッド時よりも複雑になります。マルチスレッド時の置換表の扱いは以下2通りが考えられるでしょう。
- スレッドごとに独自の置換表を持つ
- 1つの置換表を全スレッドで共有する
この2つの方法はそれぞれ一長一短あります。
前者、スレッドごとに独自の置換表を持つ場合、データ書き換えにおいて一時的に置換表をロックする必要がなくなり、この処理が高速になります。ただし、このやり方だと同一スレッド内で無駄な探索を省略することはできても、他のスレッドで探索した結果については参照できないという点で無駄が発生しやすいです。Egaroucid 7.3.0では、終盤探索時に木の末端付近でのみスレッドごとに独自の置換表を持たせています。これは、木の末端付近ではロックのコストよりも無駄な探索をするコストの方が小さいためです。なお、このアイデアはGitHubのプルリクエストで他の方からいただいたものです。
後者、全スレッドで置換表を共有する場合は、置換表を書き換えのたびにロックする必要がありますが、その分無駄な探索を大幅に減らせます。特に多数のスレッドで並列化を行う場合、ロックのコストを払ってでも効率的な探索を行った方が結果的に探索を高速化しやすいです。ただ、木の末端付近ではロックのコストが相対的に大きくなりがちなので、末端付近では置換表を使わない方が速くなります。置換表をロックする際には、置換表全体をロックするのではなく、1つの要素のみをロックするようにすると、同じタイミングで他のスレッドが置換表(の違う要素)にアクセスしようとしたときにブロックされないため、高速になります。
後ろ向き枝刈り
Egaroucidでは、様々な方法で探索を省略(枝刈り)しています。ここでは後ろ向きの枝刈り(探索結果を変えることのないもの)を紹介します。特に複雑な枝刈りはEdaxに実装されているものを参考にしています。
Negascout法
Egaroucidではminimax法系統の探索をしているので、Negascout法によって枝刈りを増やしています。Negascout法はαβ法に加え、最善(と思しき)手(Principal Variation = PV)を通常窓[α,β]で探索したら、残りの手を[α,α+1]でNull Window Search (NWS)します。これでfail highしたらPVを更新するために通常窓で探索し直して、fail lowしたらそのまま放置して良いです。
Negascoutについては、noteに詳しく書きました。
置換表による枝刈り (Transposition Cutoff)
ゲーム木はほとんど木構造として見なせるのですが、たまに合流する手筋があります。この際に同じ局面を再度探索しては無駄です。そのため、置換表(特殊なハッシュテーブル)に探索結果をメモしておきます。各ノードで探索前に置換表を参照して、値が登録されていればただちにそれを返せば良いです。また、評価値の下限値と上限値を登録しておくと、探索窓を狭める効果も期待できます。
置換表に値が登録されていたとしても、現在行っている探索よりも浅い探索の結果であればそれを採用してはいけません。Egaroucidでは評価値の下限と上限に加えて探索の深さとMulti ProbCutの確率、さらに探索の新しさを記録することで、現在行っている探索の結果として置換表の値を採用するかどうかを決定しています。
なお、置換表の参照にはオーバーヘッドがあるので、それが無視できるほど根に近いノードでのみ置換表へのアクセスを行います。根に近いノードでのみ行うことで、置換表に登録するデータを必要最低限に減らすこともできます。
さらに、置換表に過去の探索での最善手も一緒に記録しておくことで、現在の探索での手の並び替え(Move Ordering)にも使えます。
置換表による拡張した枝刈り(Enhanced Transposition Cutoff)
あるノードを探索するとき、そのノードが置換表に登録されていなくても、そのノードの子ノードを展開して置換表を参照すると、探索窓を狭めたり、評価値を確定できる場合があります。これはEdaxにてEnhanced Transposition Cutoff (ETC)として実装されているアイデアです。
あるノードを[α,β]の探索窓で探索するとします。また、子ノードを展開して、各子ノードについて置換表に記載されている(子ノードの手番から見た)最小値Lと最大値Hを見ていきます。すると、$\beta<\max(-\{L\})$であれば$\beta$を$\max(-\{L\})$に更新できますし、同様にして$\alpha>\max(-\{H\})$であれば$\alpha$を$\max(-\{H\})$に更新できます。
これは子ノードを展開した後に置換表の参照を繰り返すため、オーバーヘッドがかなり大きいです。根に近いノードでのみ行います。
確定石による枝刈り (Stability Cutoff)
ある盤面について、黒の確定石がB個、白の確定石がW個あれば、最終局面はB対64-Bから64-W対Wのどれかになるので、例えば黒目線での評価値(最終石差)は2B-64から64-2Wの中に入ることがわかります。これを用いて探索窓を狭めることができる場合があります。これはEdaxにてStability Cutoffとして実装されているアイデアです。
この手法は探索しているノードが終局に十分近い場合、つまり確定石が存在する可能性が高い場合にしか使えません。また、確定石の計算にはオーバーヘッドがありますので、あまりにも終局に近すぎると、単純に探索した方が速くなることも多くあります。
なお、確定石の個数が少ないと狭められる探索窓の範囲は-64や+64に近くなります。そのため、確定石を求める前に確定石の個数が少ないと見込まれる場合は、狭める対象の探索窓が-64や64などに近い領域を含んでいる場合のみ行います。確定石が多いと見込まれれば、狭める対象の探索窓が0に近い場合も枝刈りを試みます。確定石の個数の期待値は局面が進むにつれて増えていく傾向があるので、この見込みには深さと探索窓の上限/下限を対応づけたものを使用します。
確定石自体の計算には、
- 過去の探索での最善手(置換表に登録されている値)
- 辺の確定石(事前計算しておき、辺の形を参照して決定する)
- 8方向(縦横斜め)全てのラインが他の石で埋まっている石を確定石とする
- 確定石に8近傍を囲まれた石を確定石とする(ループで処理する)
を行っています。もちろん、これだけでは完璧に全ての確定石を求めることはできません。しかし、オセロAIの枝刈りという文脈ではこれで十分ですし、あまり正確にして遅くなっても意味がありません。
前向き枝刈り
探索結果を変えない保証のある後ろ向き枝刈りに対して、「この手は明らかに悪そうなので先読みしなくて良い」とするなどの方法を使う前向き枝刈りが存在します。前向き枝刈りは探索結果を変えてしまう可能性がありますが、後ろ向き枝刈りに比べて非常に多くの枝刈りを発生させることができ、探索スピードに貢献します。また、探索結果が変わってしまう可能性と、探索スピードの向上による読み深さの増加を比べたとき、後者の恩恵が非常に大きい場合が多いです。
Multi-ProbCut
これは古くからある手法で、Logistelloで考案(Buro 1997)されたものです。Logistello以降も現在まで様々なオセロAIで採用されています。こちらについては今後丁寧に追記予定です(2024/06/10)。
参考文献
- (Buro 1997): Michael Buro: Experiments with Multi-ProbCut and a new high-quality eval-uation function for Othello, NECI Tech. Rep. 96 (1997)
最終更新: 2025/11/29
実装上の工夫による高速化
ある局面を探索する基本的な流れは、「置換表による枝刈り→合法手生成→拡張置換表枝刈り→Muti-ProbCut→手の並べ替え→並べ替えた順番に次の局面を探索」となるわけですが、実は実装上の工夫により様々な省略が可能です。このアイデアはeukaryo氏による枝刈り手法についてという記事から得たもので、内容をアレンジしてEgaroucidで実装したものを解説します。Egaroucidでは、合法手生成から次の局面の探索までを以下の順番で実行しています。実装順序の工夫により、数%程度の高速化が見込めます。
- 置換表による枝刈り
- その場でαカットやβカットできれば、その値を返して探索終了
- 置換表には以前の探索での最善手が登録されているので、それを参照しておく
- 合法手生成
- 打てる手を全列挙
- その手によって返る石を計算
- 相手を全滅できるかを検証(全滅できたらその場でスコア+64として探索終了)
- 拡張置換表枝刈り
- 1手展開して置換表を参照し、枝刈りできないかチェックする
- 現在の探索深さに満たなくとも、以前の探索で訪れたノードは良い手の場合が多いので、その手は優先的に探索するようにメモしておく
- Multi-ProbCut
- 以前の探索での最善手を探索
- 以前最善だった手は多分今回の探索でも最善なので、手の並べ替えの前に探索してしまう
- ここでβカットが起きたらその場で探索終了してOK。手の並べかえなどに使う時間が節約できる
- 手の並び替え
- 並び替えた手を順番に探索
並列化
minimax系統のアルゴリズムはαβ法(αβ枝刈り)という手法で大幅な枝刈りを行えますが、これは逐次的に探索することを前提とした枝刈りなので、探索を並列化する場合には枝刈り効率が落ちないように注意する必要があります。
Egaroucidでは共有メモリ環境での並列化を行っているため、YBWCとLazy SMPという2つのアルゴリズムを併用しています。それぞれ紹介します。
YBWC
YBWC(Young Brothers Wait Concept)は、αβ法の並列化アルゴリズムの一つです。αβ法ではmove orderingによって最左の手(一番良い手)から順番に探索し、探索窓を効率的に狭めます。YBWCでは、ここで最左の手以外の手は(move orderingが完璧であれば)探索窓を狭めることに貢献しないことに注目しました。そこで、最左の手だけを逐次探索し、その他の手("Young Brothers")は最左の手の探索終了を待って("Wait")から並列に探索してしまいます。
なお、EdaxやEgaroucidでは、さらなる実装上の工夫として、自分のスレッドが休む時間を作らないよう、最右の2、3手程度は並列化しないようにするなどの工夫をしています。
YBWCは非常に便利な並列化アルゴリズムなのですが、並列化効率があまり良くないことで有名です。
Lazy SMP
チェスAIや将棋AIでYBWCからの乗り換え先として有効だとされているのがLazy SMPです。これは、スレッド間で置換表を共有していることをうまく利用して、それぞれのスレッドで色々な深さの探索を一斉に走らせるという並列化アルゴリズムです。実装は非常に簡単なのですが、かなり有用だとされています。
Lazy SMPは詳しい実装がまとまっているWebサイトがないのですが、私は個人的にチェスAIに関する学位論文(Østensen, 2016)を参考にしました。
Egaroucidではバージョン7.0.0より、中盤探索にLazy SMPを用いています。ただ、Lazy SMPだけだと計算時間が遅くなりすぎる場合がある(多分時間あたりの強さは向上しているのですが、決まった深さを探索するのは遅くなる場合があります)ので、YBWCも併用しています。また、終盤の読み切り以降はLazy SMPの良さが活かせないのでYBWCのみを使うようにしています。
参考文献
- (Østensen, 2016): Østensen Emil Fredrik: A complete chess engine parallelized using lazy smp, MS thesis (2016) (2025年11月現在、アクセスできなくなってしまっているようです)
最終更新: 2025/11/29
分散メモリ環境向けの並列化アルゴリズム
Egaroucidでは取り入れていないものの、分散メモリ環境向けのαβ法並列化アルゴリズムもあります。こちらは名前の紹介だけにとどめます。
最終N手最適化
オセロにおいて特徴的なのは、終盤の完全読みです。中盤探索については評価関数の精度によってミスをする可能性がありますが、完全読みさえしてしまえば、もうミスをする余地は(バグがない限り)一切ありません。
ですので、オセロAIの強さには完全読みの速さが大きく影響します。早い段階で完全読みを行えれば、オセロAIは強くなります。Egaroucidではレベルによって完全読みタイミングを変えていますが、例えばデフォルトのレベル21では24マス空き以降は完全読みを行います。また、レベル21では30マス空きから読み切り(終局まで探索するものの、悪手と思われる手を評価関数によって一部省いてしまう)も行います。
例えば24マス空きの完全読みでは1e7から1e8ほどと、それなりに多くのノードを訪問します。また、ゲーム木はその名の通り木構造ですから、葉に近いノードが非常に多いです。つまり、終局間近の数手だけ専用関数を使って頑張って高速化すれば、完全読み全体を高速化できる見込みがあるのです。
ということで、ここでは最終N手最適化として、Egaroucidで用いている最終1手から4手の最適化手法を解説します。
現実的には終局間近かどうかの判定は難しいので、盤面に空きマスが何マスあるかを見て専用関数への移行を行います。
1マス空きの最適化
通常、石数のカウントは盤面に石を置いた後に盤面の石を数えて行いますが、1マス空きについては、もはや盤面に石を置く処理すら不要です。必要なのは、
- 現在の盤面の石差
- 空きマスに着手したときに返る石の数
の2つの数だけです。
現在の盤面の石差は、盤面が必ず1マス空きであるという特性を利用すれば、一方のプレイヤの石数をカウントするだけで計算できます。
空きマスに着手したときに返る石の数は、専用関数を作って求めます。空きマスから縦横斜めの4方向についてそれぞれ返る石の数を求めて合計します。このとき、各ラインで返る石の数は事前計算で求めておいて、実際の探索ではラインの抜き出しと表引きで実装しました。
また、現在の盤面の石差を求めた時点で探索窓に比べて明らかに枝刈りできる場合は、返る石の数の計算を省略することも可能です。
なお、返る石の数が0であればパスの処理をしたり、両者置けない場合はそのまま終局にしたりするなどの処理が必要です。ここで、1マス空き(奇数マス空き)で終局するときには引き分けが存在しないことを利用すると、終局の処理を若干高速にできます。
2マス空きの最適化
2マス空きでは合法手生成を省いて、簡易的に空きマスの周りに相手の石があれば合法手として返る石を計算し、返る石があれば着手するという処理を行いました。
なお、2マス空きでは偶数理論もどき(手の並び替えの項目を参照)に意味がないため、手の並び替えは行いません。ただ、2連打が確定する手筋があればそちらを優先する(つまり、相手からも置ける可能性のあるマスを優先して探索する)などの工夫ができます。
3マス空きの最適化
3マス空きでは、偶数理論もどきによって手の並び替えを行えます。盤面のそれぞれの象限を見て、ある象限には1マス、別の象限では2マスの空きマスがあれば、1マスの空きを優先して着手します。この並べかえでは条件分岐をなくすため、マスの位置(0から63で表す)と象限を対応付けるbitをうまく使って、SIMDのshuffle関数と表引きを使うことで並び替えを実現しています。このアイデアはEdaxをAVXに最適化した奥原氏の解説を参考にしました。
3マス空きでも2マス空きと同じように、合法手生成を省いて簡易的に合法手判定をして、順番に着手を試みます。3マス空きで終局する場合は、引き分けが存在しないので引き分けの処理を省いた関数で石差を計算します。
4マス空きの最適化
4マス空きでは、偶数理論もどきによって手の並べ替えを行います。象限ごとに1マス-1マス-2マス-0マスの空きがある場合、1マス空きの象限2つを優先して探索します。これも条件分岐をなくすため、3マス空きと同じようにshuffleを用いた最適化を行いました。
4マス空きでも合法手生成を省いて簡易的に合法手判定をして、順番に着手を試みます。
特殊な終局への対策
Egaroucidは序盤で中盤探索を行います。これは終局まで読みきらずに評価関数による評価値を探索結果として使った探索です。
しかし、当然ながら評価関数は完璧ではありません。例えば大量取りされた場合、圧倒的に有利なはずなのに間違って全滅筋に入ってしまうなど、評価関数だけでは見抜けない特殊な終局があります。
例えば以下の局面は白番ですが、白が圧倒的に有利な状況にあります。しかし、間違ってe6に白が置いてしまうと、黒e3で全滅して白は負けてしまいます。
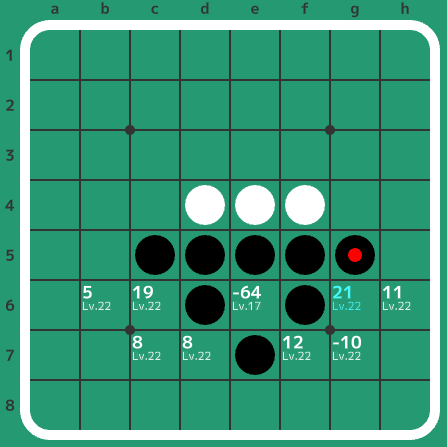
こういった特殊な終局(有利だが一手だけ大悪手があるなど)の回避のため、Egaroucidではある程度の深さの考えうる全部の手を高速に列挙し、こういった特殊な終局が発見されないかを確認してから中盤探索を行っています。純粋にビットボードの処理だけしかしないため、非常に高速に実装できます。
GPUを使った探索
Egaroucidではバージョン7.7.0現在、CPUのみを使って探索を行っています。しかし、GPUを使って探索すればもっと高速化できるのではないかと考え、実験してみたことがあります。先人の取り組みも含めて軽く解説します。全体を通して、残念ながらCPUによる探索を置き換えるほどの成果は出ていません。
最終更新: 2025/11/29
私による2024年の研究
GPUを使って終盤局面の探索を行う手法を考案し、CPUとGPUで実行時間等の比較を行いました(山名 2024)。
この研究では、2種類のロードバランスアルゴリズムと簡易的なmove orderingアルゴリズムを使用した、部分的な並列αβ探索です。ロードバランスは問題単位のロードバランスと問題分割によるロードバランスを行いました。
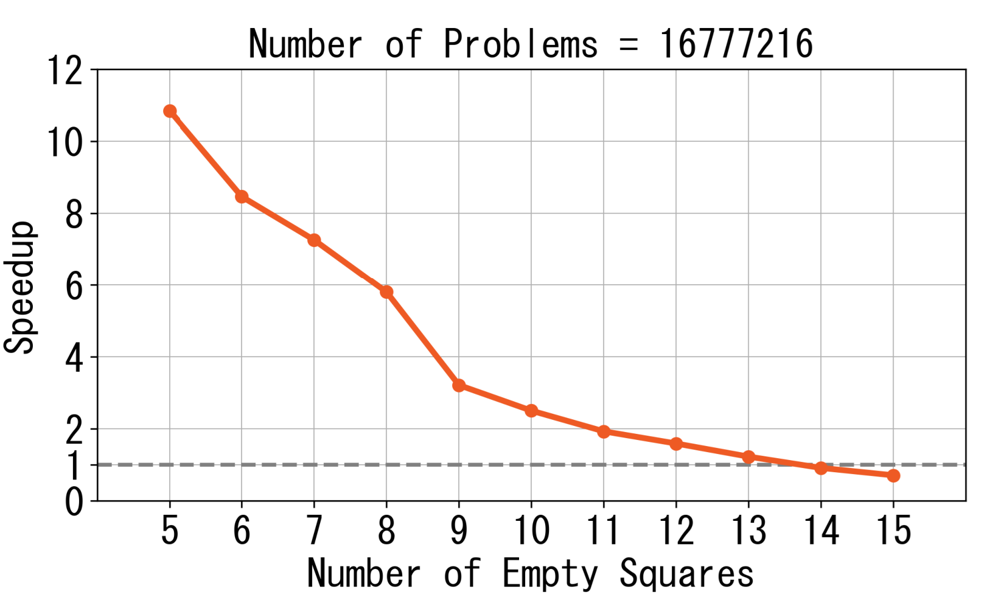
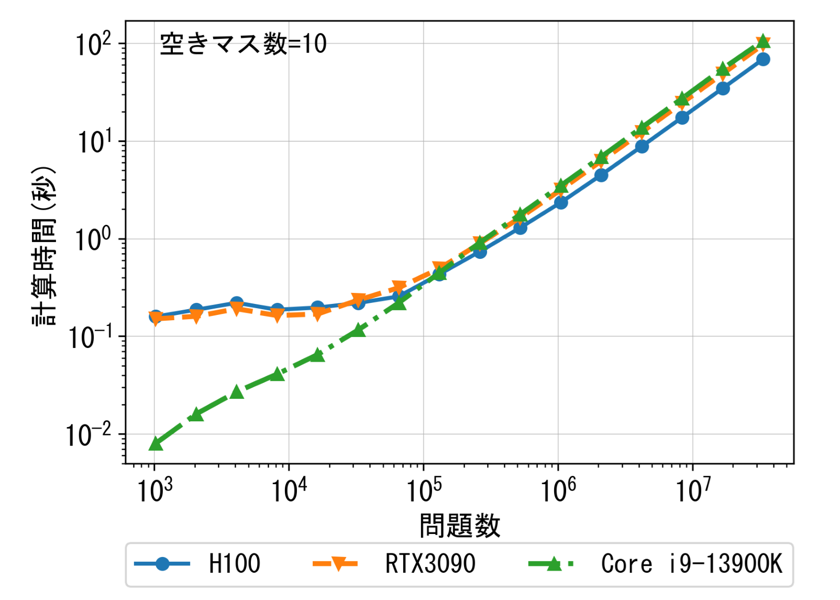
GPUとしてRTX3090、CPUとしてCore-i9 13900Kを使い、CPUに対してGPUでどれくらい高速化できたかを調査しました。その結果が以下のグラフです。縦軸が1を超えていれば、GPUがCPUより速いことを表します。このグラフでは問題数を$2^{24}=16777216$に固定し、空きマス数(読み深さとほぼ同じ)を変化させて探索時間を計測しました。その結果、13マス空き(13手程度読み)までならGPUがCPUより速かったのですが、それ以上の空きマス数だとCPUの方が速いという結果になりました。
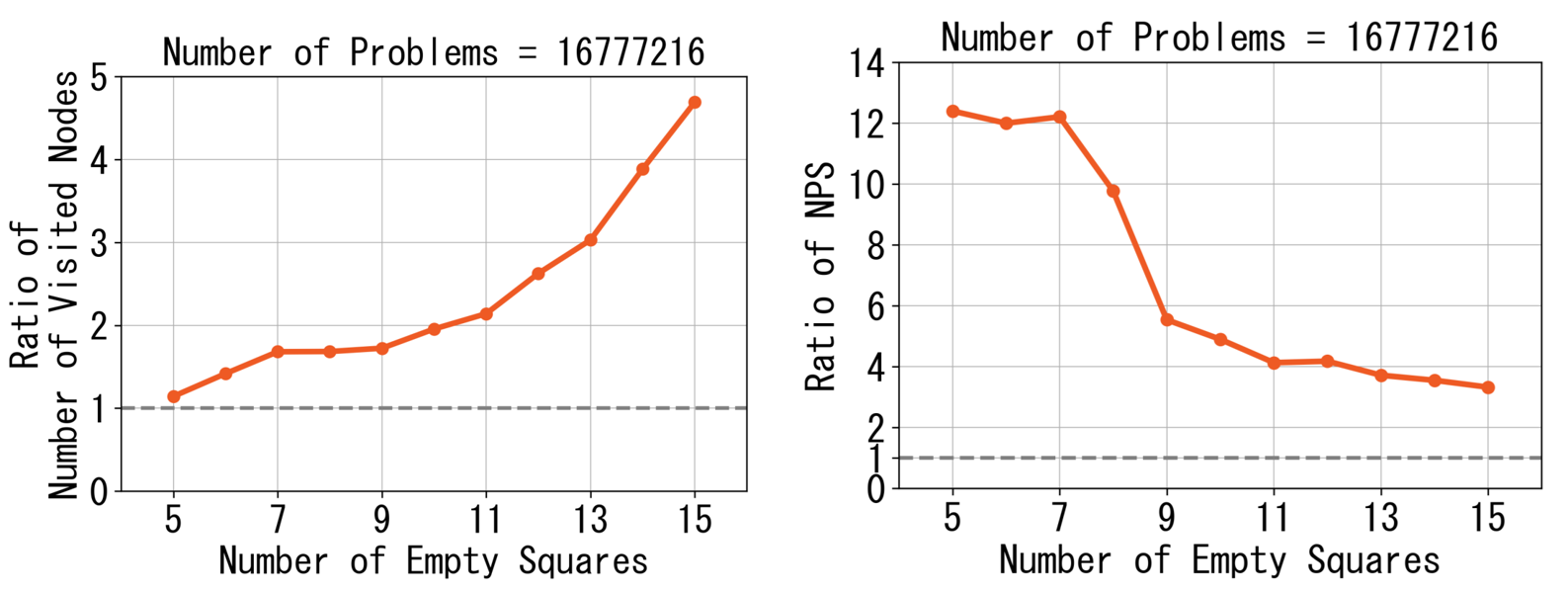
さらに、問題数を固定して空きマス数を変化させたときの訪問ノード数、NPSについて、それぞれCPUとの比をプロットしました。空きマス数が増えると、GPUでは訪問ノード数が飛躍的に増え、NPSが徐々に落ちていくことがわかります。訪問ノード数の増加はGPU版のmove orderingがCPU向けのものより簡素なためと思われます。NPSの減少は、ロードバランスアルゴリズムの限界によるものだと思われます。
上の例では問題数を固定しましたが、空きマス数を固定して問題数を変化させる実験も行いました。少し古いコードでの実験ですが、掲載します。問題数が概ね$10^5$を超えると、GPUでトップスピードが出ているということがわかります。GPUは大量のスレッドをいかに並列稼働させるかが高速化の鍵なので、私の作ったアルゴリズムだと、GPUの性能を引き出すためには多くの問題が必要になりました。私のコード以外のどんなアルゴリズムであっても、GPUで探索するのであれば一定の問題数がないとトップスピードが出ないと思います。
参考文献
- (山名 2024): 山名琢翔: GPGPUによるαβ法を用いた高速なオセロ探索手法, 研究報告ゲーム情報学(GI), Vol. 2024-GI-51, No. 26, pp. 1-9 (2024)
最終更新: 2025/11/29
そすうぽよ氏による2016年頃の取り組み
GPUを使って10マス空き1091780局面の完全読みを行った取り組み(そすうぽよ 2016-2018)です。様々な工夫をした結果、GPU (GTX1080) で9秒以下、CPU (Core i7-6700K)で1分13秒だったとのことです。
通常は探索を再帰で書くのですが、これをループに展開し、Shared Memoryにスタックの内容を保持することで高速化したようです。さらに4スレッドをSIMD的に使って、4スレッドで1局面を読むという工夫による高速化もしています。
関連コードがGitHubで公開されています(そすうぽよ 2024)。
参考文献
- (そすうぽよ 2016-2018): そすうぽよ: GPGPUで爆速でオセロを解く (2016-2018)
- (そすうぽよ 2024): そすうぽよ, primenumber/GPUOthello2: GPUOthello2
最終更新: 2025/11/29
奥原氏による取り組み
GPUを使って5マス空きの完全読みを行った取り組み(奥原 20XX)があります。これは通常のαβ法ではなく、すべての空きマスに(非合法手も含めて)着手してみる総当り探索を行ったものです。そのため、5マス空きであれば$5!=120$通りの探索を行っています。
この方針だと結局CPUでのαβ法よりも1桁遅い結果になったとのことです。引用したページにコードも公開されています。
参考文献
- (奥原 20XX): 奥原俊彦: GPU computingによるbitboard実装の実験
最終更新: 2025/11/29
ゲームの特性
ここには、オセロAI制作の副産物として得たオセロというゲーム自体についての知識をまとめます。
オセロの序盤の展開数
オセロは1手打った局面は、対称的な形を同一視すると1通りあります(4つどこに打っても同じなので)。2手打った局面は3通りです(縦取り、斜め取り、平行取り)。このように考えていくと、オセロの序盤の展開の総数がわかります。これをコンピュータで計算してみました。なお、「対称的な形を同一視」とは、回転や線対称、点対称で一致する局面をすべて同一視したという意味です。また、途中で終局した場合、その局面は終局後はカウントしていません(オセロは最短9手で終局しますが、例えば9手で終局した局面は10手以降にはカウントしません)。
| 打った手数 | 局面数 |
|---|---|
| 0 | 1 |
| 1 | 1 |
| 2 | 3 |
| 3 | 14 |
| 4 | 60 |
| 5 | 322 |
| 6 | 1773 |
| 7 | 10649 |
| 8 | 67245 |
| 9 | 434029 |
| 10 | 2958586 |
| 11 | 19786627 |
| 12 | 137642461 |
実はこの情報はEgaroucidの評価関数を生成するとき、「序盤$N$手まではすべての展開を学習データとしよう」と思い、その$N$を適切に決めるために調べたものです。
ちなみに、先人も似たような計算をしており、初手だけを固定し、その後に出てくる進行数を数えたものや、局面の同一視を一切行わないもの(Perft for Reversi)があります。
状態空間の大きさの推定
オセロというゲームの"複雑さ"について考えてみます。ゲームの複雑さを考えるときには、そのゲームで実現可能な局面数(合法局面数)や、そのゲームで実現可能な棋譜の数(ゲーム木サイズ)を使うことが多いです。この2つの値は非常に紛らわしいので、まずはこれらの数値の違いについて解説し、その後、各数値に関する最新研究を(私が知る限りで)紹介します。
合法局面数は英語版Wikipediaなどで$10^{28}$という値がよく知られていますが、2025年現在では$10^{25\sim26}$と見積もった最新研究があります。また、ゲーム木サイズについては俗説として$10^{58\sim60}$という値がよく知られていますが、2006年頃の匿名の議論および2019年の研究で$10^{54}$という見積もりがあります。
最終更新: 2025/12/28 (Yong et al. 2019)の内容を追加
合法局面数とゲーム木サイズの違い
ゲームの複雑さを示す数字には2種類あり、非常にわかりにくいので軽く解説します。たまに「オセロの状態数は$10^{58\sim60}$」などの記述を見かけるのですが、これは合法局面数(State-space complexity)とは別の数字で、ゲーム木の大きさ(Game tree size)を念頭に置いた数字です。
合法局面数は、初期盤面からたどり着ける局面の数を数えたものです。つまり、そのゲームで存在する局面の数そのものを表します。一方でゲーム木のサイズはゲーム木の葉ノードの数で、そのゲームであり得る棋譜の数と同じになります。
一般に、ゲーム木サイズは合法局面数よりも大きな値になる傾向があります。例えば、オセロだとf5d6c3d3c4とf5d6c4d3c3は違う棋譜(虎定石に虎系から行くか猫系から行くか)ですが、全く同じ状態となります。合法局面数を数える場合はこれらの局面を同一視しますが、ゲーム木の大きさを考えるときには別物として考えます。こういった、違う棋譜で同じ状態にたどり着くという状況はオセロで非常に多く発生します。そのため、ゲーム木サイズは合法局面数よりも多くなります(そもそもこの2つの数字は全く違うものを数えているのですが)。
オセロのゲーム木サイズの$10^{60}$という見積もりは、オセロでは大体1つの局面あたり10手の合法手があり、対局が大体60手で終わることを根拠に得られた数字だと思われます。なお、$10^{58}$はおそらく、1手目の対称性を考慮して1手分、最終手は選択の余地がないので1手分減らした結果得られた数字だと思われます。しかし、9マス空き以降は自明に合法手が10手を切りますし、序盤の合法手数は10より少ないことも多いです。その一方で、中盤の合法手数は10手を超えることも多いです。そのため、ゲーム木サイズの推定としては精度を期待できるものではありません。
ちなみに、オセロの合法局面数の自明な上界は、中央4石の配置(黒/白)とその他60マスの配置(黒/白/空)を考えて、$2^4\times3^{60}=6.783\times10^{29}$です。この数値がゲーム木サイズとして俗に言われている$10^{58}$よりも極端に小さいことを見ても、$10^{58}$は合法局面数を表す値としては不適であることがわかります。
最終更新: 2025/11/30
合法局面数 - 石井・田中による2025年の研究
(石井・田中 2025)および(石井・田中 2025 発表スライド)、(石井・田中 2025 正誤表)では、オセロの合法局面数を推定しています。その結果、オセロでは有意水準99.5%で$4.488\times 10^{25}$から$1.127\times 10^{26}$の合法局面が存在することがわかったとのことです。
この研究では、盤面にランダムに石を配置した局面を100万個ランダムに生成し、その中で合法局面がいくつあったかを数えることで、オセロの合法局面数を推定しています。ランダム局面の合法性を確かめる手法は非常によく考えられており、面白い(がゆえに私も全部を把握しきれていない)ので、論文・コードをぜひお読みください。合法性の判定は論文内での説明だけでなく、公開されているコード(石井・田中 2025 GitHub)を見ると非常に詳しく理解できるようで、私も勉強中です。また、この研究では合法性が不明になった局面も存在しますが、それもうまく統計的に考慮していて、非常に興味深いです。
なお、この研究では、対称的(線対称・回転対称)な盤面を同一視しています。また、同じ局面が違う手番で発生する場合も同一視しています(オセロだとこのような局面は稀でしょうが)。
参考文献:
- (石井・田中 2025): 石井颯太郎, 田中哲朗: オセロの実現可能局面数の推計, ゲームプログラミングワークショップ2025論文集, Vol. 2025, pp.171-178 (2025)
- (石井・田中 2025 発表スライド): 石井颯太郎, 田中哲朗. u-tokyo-gps-tanaka-lab/othello_complexity_rs: オセロの実現可能局⾯数の推計
- (石井・田中 2025 正誤表): 石井颯太郎, 田中哲朗. u-tokyo-gps-tanaka-lab/othello_complexity_rs: オセロの実現可能局面数の推計 正誤表
- (石井・田中 2025 GitHub): 石井颯太郎, 田中哲朗. u-tokyo-gps-tanaka-lab/othello_complexity_rs
最終更新: 2025/12/28 石井・田中の正誤表の内容を追加
ゲーム木サイズ - 匿名の議論の結果
2005年から2006年にかけて、オセロのゲーム木サイズを推定する議論が行われました(@WIKI 2005-2006)。この議論では最終的にゲーム木サイズが$6.449\times10^{54}$と推定されました。基本的な方針は、ランダム対局によって各手における合法手数のデータを得て、それをもとに推定するものです。このとき、n手目の局面m個の合法手数の平均を取るのではなく、「n手目までの各局面における合法手数の積」の(相加)平均を取るというのが工夫のようです。
なお、この数値は打てる手の対称性を考慮していないもののようです。例えば初手に打てる場所は4つ(d3、c4、f5、e6)あるものの、どれも本質的には同じ手です。しかし、ここではこれらの手をすべて別物として考えています。
(@WIKIのメモ 2006)には、各深さでのゲーム木サイズの推定が書かれていますが、この21手目までの値は(Brobecker et al. 2006-2021)で示された厳密な値とかなり近いことが読み取れます。
参考文献:
- (@WIKI 2005-2006): オセロの試合結果は何通りか?@Wiki (2005-2006)
- (@WIKIのメモ 2006): メモ05手数の積の平均, オセロの試合結果は何通りか?@Wiki (2006)
- (Brobecker et al. 2006-2021): Alain Brobecker, Paul Byrne, Charles R Greathouse IV, and Dominic Hofer: Number of possible Reversi games at the end of the n-th ply. (2006-2021)
最終更新: 2025/11/30
ゲーム木サイズ - Alexander YongとDavid Yongによる2019年の研究
(Yong et al. 2019)では、オセロのゲーム木サイズを$6.47(\pm0.19)\times10^{54}$と推定しています。この研究では、上記の2005年から2006年にかけての匿名の議論とほぼ同じ方法により、ほぼ同じ数値が得られています。
この研究ではオセロの棋譜において出現する各局面での合法手の総積をゲーム木サイズと見積もっています。実際にはランダムプレイによるオセロの棋譜を$2\times10^6$個用意し、$6.47(\pm0.19)\times10^{54}$というゲーム木サイズを得たとのことです。なお、$(\pm0.19)$の部分は標準偏差とのことです。
この研究ではオセロの他にも3目並べと4目並べのゲーム木サイズを見積もっています。
参考文献:
- (Yong et al. 2019): Alexander Yong, David Yong: An estimation method for game complexity. arXiv preprint arXiv:1901.11161 (2019)
最終更新: 2025/12/28 (Yong et al. 2019)の内容を追加
合法局面数 - 私による雑な推定
とりあえず初手からたどり着けるかどうかは考えないで試算してみます。オセロは64マスのボードで構成されていて、それぞれのマスについて黒か白か空きかの3種類が考えられるので、$3^{64}=3.4\times10^{30}$が状態空間の大きさの上界となります。最初に4マス埋まっている(黒か白の2種類しかない)ことを考えると$2^4\times 3^{60}=6.8\times 10^{29}$です。
また、1手ごとにどれくらいの局面数があるかを考えます。$p$手目について考えうる合法な局面の数$s(p)$を概算すると、
$s(p)=2^4 \times {}_{60}\mathrm{C}_p \times 2^p$
と考えることができます。第一項は最初に埋まっている4マスの組み合わせ、第二項は残りの60マスで$p$マスを石で埋める埋め方、第三項は$p$手目までで埋まった石の色の組み合わせです。これを$0\leq p \leq 60$で計算すると、以下のグラフのようになります。序盤から40手目付近までで局面の数が増えて、それ以降は終局に近づくにつれて局面数が少し減っています。青線は参考として書いた上界です。また、$p \leq 12$までは上で序盤の展開数を全て求めたので厳密な値がわかります。それもプロットしてみました。
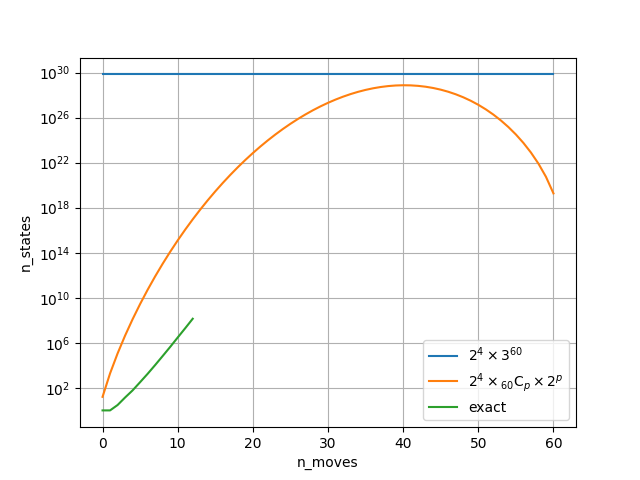
この上界はあまり精度が良くないとわかりますが、まあとりあえず仕方がないということにします。
状態空間の大きさを推定するほかの手法として、評価関数の大きさと汎化性能の関係を調べることも役立つ可能性がある気がしています。例えば、Egaroucidの評価関数学習結果は45手目付近でtest_mseが最大となっていました。そのため、上のグラフでは40手目付近にあるピークが、本当は45手目付近にあると想像することができるかもしれません。
最短引き分け
オセロでは多くのマスが空いた状態で終局することがありますが、ここでは盤面がスカスカの状態で引き分けに終わる状態を考えます。
最短引き分けは20手で、185通りの棋譜(f5始まりに統一)がありました。以下が棋譜の例です。
f5f4c3f6g7f7f3h7f8b2h6e7h8e3d7g3f2f1a1c5
f5f4c3f6g7f7f3h7f8b2h6e7h8e3d7g2f2f1a1c5
f5f4c3f6g7f7f3h7f8b2h6e3a1e7f2f1h8e2d7c5
f5f6e6f4g7c6f3g2f2f7b7a8h2f1f8h3e2h1c4d2
f5d6c6b6b7f6b5a6e6a8b8f3f7g6g2c8h6h1d3b4
f5d6c6b6b7f6b5a6f7f3g2b4e6g6b3h1h6a8d3b2
f5f6e6f4g5c6f3g2f2f7b7a8h2f1f8h3e2h1c4d2
f5f4g3e6c4b3b4g4f7g8b2a2h4b5b6a4d7b7d6b1
f5f4g3e6c4b3b4g4b2a4f7c2h4g8d2d1d7e2d6a2
f5f4g3e6c4b3b4g4f7g8b2a2d6b5b6c2h4a4d7b7
終局結果は線対称・点対称・回転対称を同一視して10通りありました。

最短引き分けの詳しい解説記事をQiitaに書きました。また、この結果を求めるために使ったコードをGitHubにて公開しています。
最短引き分けのうち一つは私の取り組み以前に人力で見つかっていました。人力探索の解説記事がnoteに公開されています。
最短ストナー
オセロにおいてストナーという戦術があります。ストナーは最短で対局開始から13手で発動します。13手ストナーの一例は以下です。
e6d6c6d7c8b6c7f7f6e8f8g8b7

最短ストナーを求める詳しい解説記事をQiitaに書きました。また、この結果を求めるために使ったコードをGitHubで公開しています。
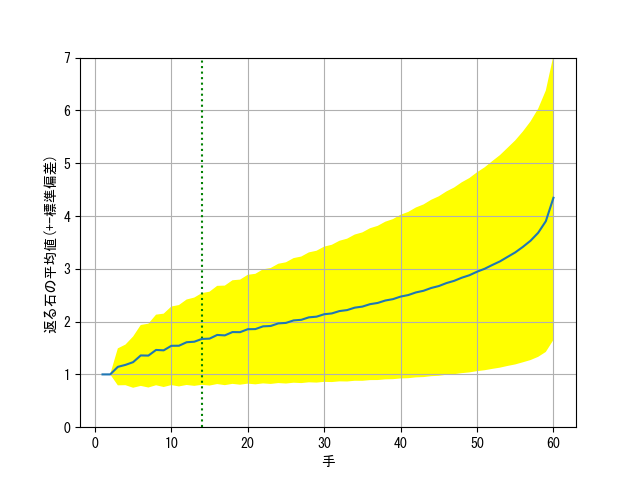
返る石数の平均値
オセロにおいて、返る石の平均値はいくつでしょうか。これを概算してみました。その結果、1手目から60手目まで、合法手1手で返る石の数は、大体2.244枚であるとわかりました。この実験に使ったコードはこちらに公開しています。
1手ごとにこの結果をプロットすると以下のようにあります。青色の線が平均を示し、黄色の区間は平均±標準偏差の領域を表します。つまり、適当な盤面を用意して適当な手を打ったときに返る石の数は、(返る石の数の分布を二項分布と見做すと)約68%の確率で黄色の領域に入るということを表します。平均値が黄色の区間の範囲でブレるというわけではありません。
なお、序盤14手(緑の縦線)まではありうる状態を全列挙して計算した結果で、厳密なものです。15手目以降は$10^7$回の対戦(ランダム打ちによる)によって推定した結果です。
参考となる資料
私自身がオセロAI初心者から今に至るまでに参考とした資料(など)の紹介です。
コードを公開しているオセロAIや、独自のアルゴリズム解説を行っているオセロAI、そしてオセロAI開発におすすめの本などを紹介します。順不同です。
文書・記事
オセロAIの教科書
私が以前書いたものです。このサイトとは違い、基礎的なところから丁寧にサンプルコードをつけて書いてあるので、学習しやすいと思います。ただ、少し内容が古いです…いつか更新します。
ゲームで学ぶ探索アルゴリズム実践入門
ゲームAIのコンテストで活躍するthunderさんによる本と、その元になった記事です。出版時期の関係で私自身がリアルタイムに参考にすることはできなかったのですが、オセロAIに限らず探索アルゴリズムを広く学べる良い本です。オセロAI的にはαβ法の枝刈りの説明が非常にわかりやすく、おすすめです。
実は私がオセロAI開発を始める1ヶ月ほど前、偶然にもthunderさんにminimax法について教えていただく機会がありました。
リバーシプログラムの作り方
オセロAI制作について、初歩から丁寧に解説している記事集です。私自身は特にMPC (Multi-ProbCut)の解説を参考にしました。また、サンプルプログラムも付属しています。若干古い記事のようですが、今でも役立つ情報がたくさん書かれています。
Chess Programming Wiki
チェスAIを念頭に、ゲームAI関連の様々な情報が載っています。記述が少ない項目もいっぱいあるのですが、引用している文献をたどるという使い方もでき、有用です。
オセロAI
Edax
Edaxは広く使われている強豪オセロAIです。すべての方面で非常にバランス良くできており、コードを読むととても勉強になります。GitHubでバイナリの他、全部のコードが公開されており、私は全部印刷してたまに読んでいます。
Edax-AVX
EdaxをSIMD化し、高速化したものです。EdaxはCPUレベルの命令などを使っておりませんが、これは様々なSIMD化によってEdaxを定数倍高速化しています。私が知る中では最速のオセロAIです。ちなみにオセロを弱解決したという論文では、このオセロAIで探索を行ったと書いてあります。また、SIMD化を行った奥原氏によるオセロAIのSIMD化に関する様々なテクニックの(日本語の!)解説は大変参考になります。Edax-AVXのコードも公開されており、こちらも私は印刷してたまに読んでいます。
Thell
2005年頃まで開発されていたオセロAIです。技術情報を(日本語で!)独自で公開しています。特に評価関数に関する資料が非常に有用です。なお、Thellはボードの実装方法が独特で、私自身も試してみたのですが、結局Thellの方法ではなくビットボードが速いという結論に至りました。
Zebra
少し古いオセロAIですが、Edax以前にはオセラーに「これ一択」として使われていたというオセロAIです。独自で技術解説を(英語で)公開している他、巨大なBookも無償公開しています。ただ、現代のオセロAIでこのBookを見ると、精度が非常に高いとは言えません。それでもBook生成の種としては非常に有効に使えると思い、Egaroucidでは許可を得てZebraのBookをもとに独自Bookを作りました(とは言え、もう原型はほぼありません…)。なお、技術解説については日本語に翻訳してくださった方がいらっしゃるため、そのリンクも載せます。
Logistello
1997年に人間の世界チャンピオン(村上健七段(当時))と戦い、勝利したオセロAIです。非常に古いオセロAIですが、作者による論文はオセロAI開発ならびにオセロAIの歴史を知る上で非常に役に立ちます。
- LOGISTELLO
- Experiments with Multi-ProbCut and a New High-Quality Evaluation Function for Othello
- From Simple Features to Sophisticated Evaluation Functions
- Takeshi Murakami vs. Logistello
FOREST
ここまでのオセロAIとは少し毛色の違うオセロAIとして、FORESTがあります。これは深層学習をαβ法に取り入れたオセロAIで、探索中に推論しているという特徴があります。評価関数の精度に振り切った設計だと思われます。また、FORESTは1994年から2023年現在までずっと開発が継続されており、歴史があります。英語の技術文書と、それを日本語に翻訳して公開されているものがあります。